
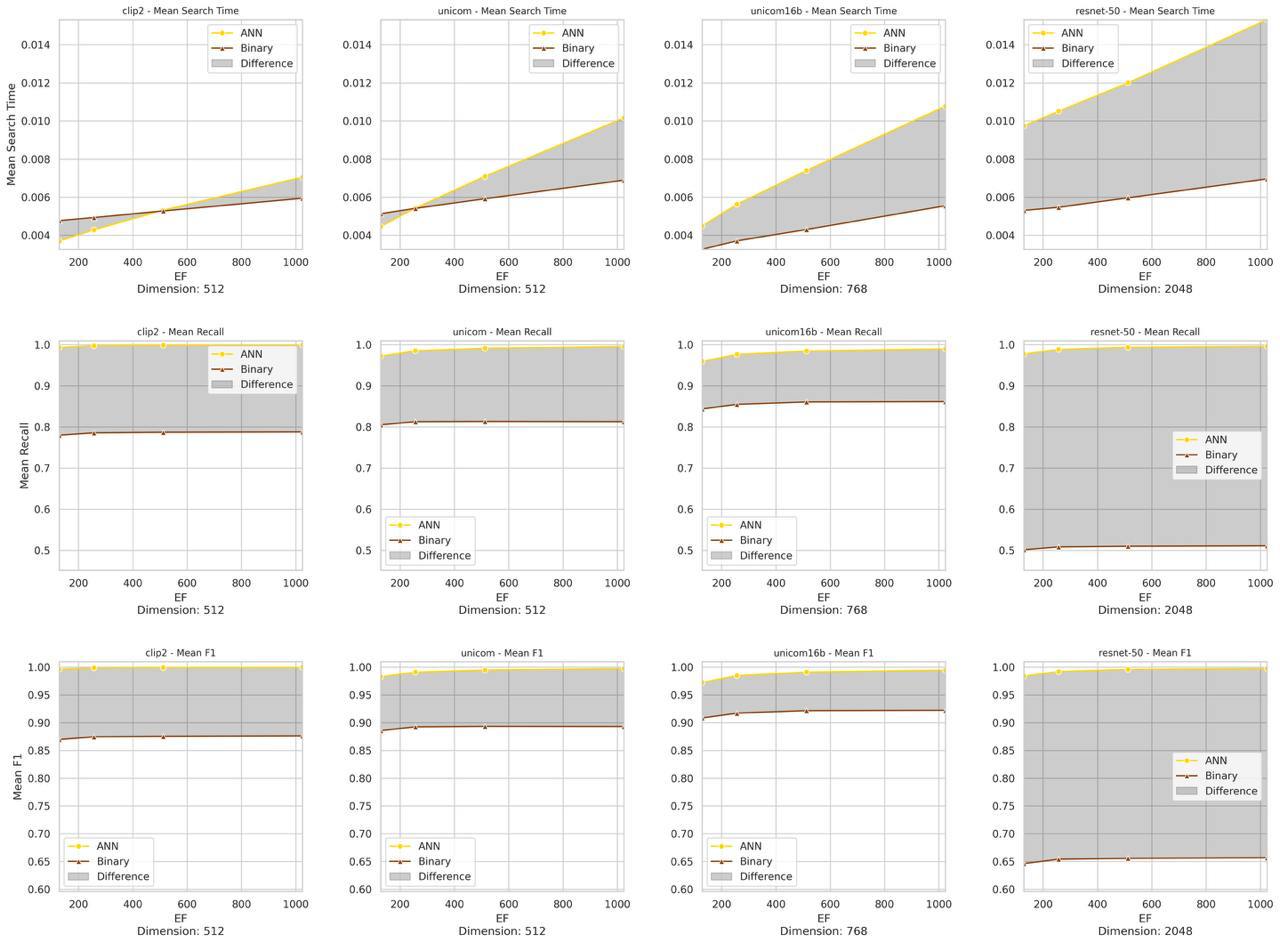
Как ведет себя поиск по эмбедингам разных моделей при применении Binary Quantization?
Аккуратно, контент сложноприкольный. Возможно стоит перечитать пару последних постов отсюда
Собрав все предыдущие посты вместе, хочу поделиться недавними экспериментами.
У Qdrant есть не только векторная база данных, но и fastembed, питонический пакет для быстрого и простого извлечения эмбеддингов. Быстро — потому что поддержка параллелизации встроена из коробки и работает без лишних усилий на разных бекендах. Просто — потому что минимум зависимостей и все они лёгкие, без необходимости тянуть за собой 3 Гб torch или 1.5 Гб Tensorflow. Эмбеддинги можно извлекать как из текстов, так и из картинок.
Из четырёх моделей для картинок я добавил в репозиторий три, что позволило легко использовать именно этот инструмент.
Вопросы, которые я себе задал:
1. Как влияет использование разных моделей на производительность Qdrant?
2. Как изменяется время поиска для разных моделей при увеличении параметра EF (который отвечает за количество связей на очередном слое HNSW)?
3. Какие модели наименьшим образом деградируют при переключении в режим BQ?
4. Что объединяет модели, которые работают с BQ хорошо и плохо?
Для ответа на эти вопросы я взял 10% данных Imagenet с любимого Kaggle, заэмбеддил их и залил в базу. Бенчмарк сравнивал метрики качества поиска с Exact search (честное сравнение каждого запроса со всеми объектами в базе) по метрике Dot_product. Для тестирования использовал все доступные в fastembed модели для картинок:
clip-ViT-B-32-vision — живая классика.
Unicom-ViT-B-16 — специальная модель из open metric learning.
Unicom-ViT-B-32 — тоже модель для open metric learning (по менбше).
ResNet50 — полуживая классика.
Основные выводы:
1. Время поиска линейно зависит от параметра EF, а скорость поиска — от размера эмбеддингов.
2. Качество поиска от EF скейлится логарифмически, что делает этот компромисс очень выгодным.
3. ResNet50 плохо работает с BQ, в то время как модели, специально обученные для metric learning, показывают минимальную деградацию.
Общий вывод:
Если бы я начинал стартап по поиску похожих лиц, то выбрал бы Unicom-16b. Это позволило бы при росте числа лиц легко переключиться на Binary Quantization с оверсемплингом и минимально потерять в качестве.
А теперь приглашаю к обсуждению в комментариях:
1. Влияет ли loss-функция, на которую обучалась модель, на её деградацию в BQ?
2. Какие модели стоит ещё попробовать?
3. Какую другую метрику близости стоило использовать для сравнения и почему?
Аккуратно, контент сложноприкольный. Возможно стоит перечитать пару последних постов отсюда
Собрав все предыдущие посты вместе, хочу поделиться недавними экспериментами.
У Qdrant есть не только векторная база данных, но и fastembed, питонический пакет для быстрого и простого извлечения эмбеддингов. Быстро — потому что поддержка параллелизации встроена из коробки и работает без лишних усилий на разных бекендах. Просто — потому что минимум зависимостей и все они лёгкие, без необходимости тянуть за собой 3 Гб torch или 1.5 Гб Tensorflow. Эмбеддинги можно извлекать как из текстов, так и из картинок.
Из четырёх моделей для картинок я добавил в репозиторий три, что позволило легко использовать именно этот инструмент.
Вопросы, которые я себе задал:
1. Как влияет использование разных моделей на производительность Qdrant?
2. Как изменяется время поиска для разных моделей при увеличении параметра EF (который отвечает за количество связей на очередном слое HNSW)?
3. Какие модели наименьшим образом деградируют при переключении в режим BQ?
4. Что объединяет модели, которые работают с BQ хорошо и плохо?
Для ответа на эти вопросы я взял 10% данных Imagenet с любимого Kaggle, заэмбеддил их и залил в базу. Бенчмарк сравнивал метрики качества поиска с Exact search (честное сравнение каждого запроса со всеми объектами в базе) по метрике Dot_product. Для тестирования использовал все доступные в fastembed модели для картинок:
clip-ViT-B-32-vision — живая классика.
Unicom-ViT-B-16 — специальная модель из open metric learning.
Unicom-ViT-B-32 — тоже модель для open metric learning (по менбше).
ResNet50 — полуживая классика.
Основные выводы:
1. Время поиска линейно зависит от параметра EF, а скорость поиска — от размера эмбеддингов.
2. Качество поиска от EF скейлится логарифмически, что делает этот компромисс очень выгодным.
3. ResNet50 плохо работает с BQ, в то время как модели, специально обученные для metric learning, показывают минимальную деградацию.
Общий вывод:
Если бы я начинал стартап по поиску похожих лиц, то выбрал бы Unicom-16b. Это позволило бы при росте числа лиц легко переключиться на Binary Quantization с оверсемплингом и минимально потерять в качестве.
А теперь приглашаю к обсуждению в комментариях:
1. Влияет ли loss-функция, на которую обучалась модель, на её деградацию в BQ?
2. Какие модели стоит ещё попробовать?
3. Какую другую метрику близости стоило использовать для сравнения и почему?