




AI для Всех
Канал, в котором мы говорим про искусственный интеллект простыми словами
Главный редактор и по рекламе: @crimeacs
Иногда пишут в канал: @GingerSpacetail, @innovationitsme Связанные каналы | Похожие каналы
12 899
obunachilar
Kanalda mashhur

Закончились 12 дней Open AI, по этому поводу сделал вам песню про все что показали.

🔍 Как быстро собрать весь код из проекта для подачи в LLM В последний месяц, по разным причинам,...
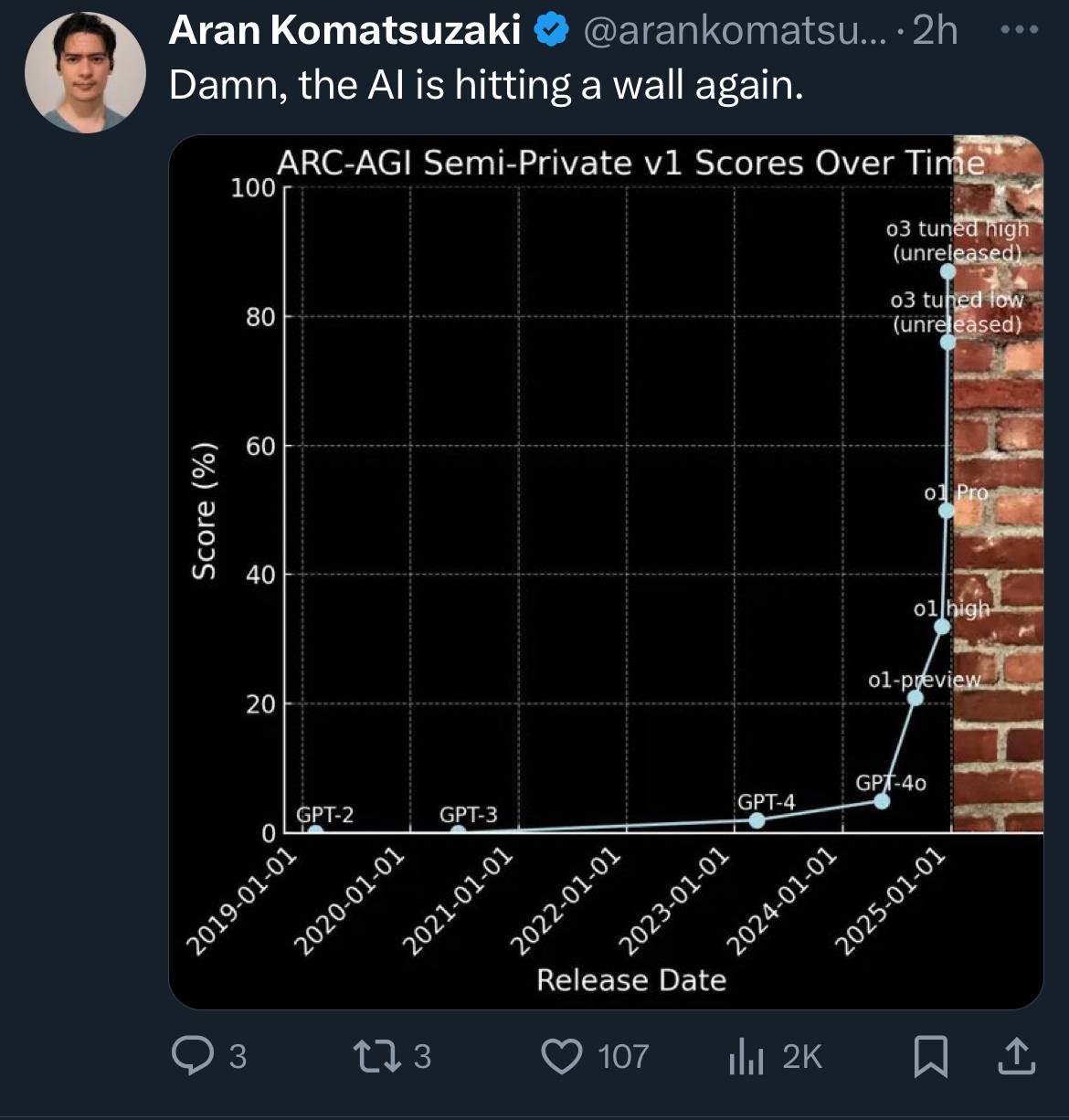
Ох уж эта стена 🤣
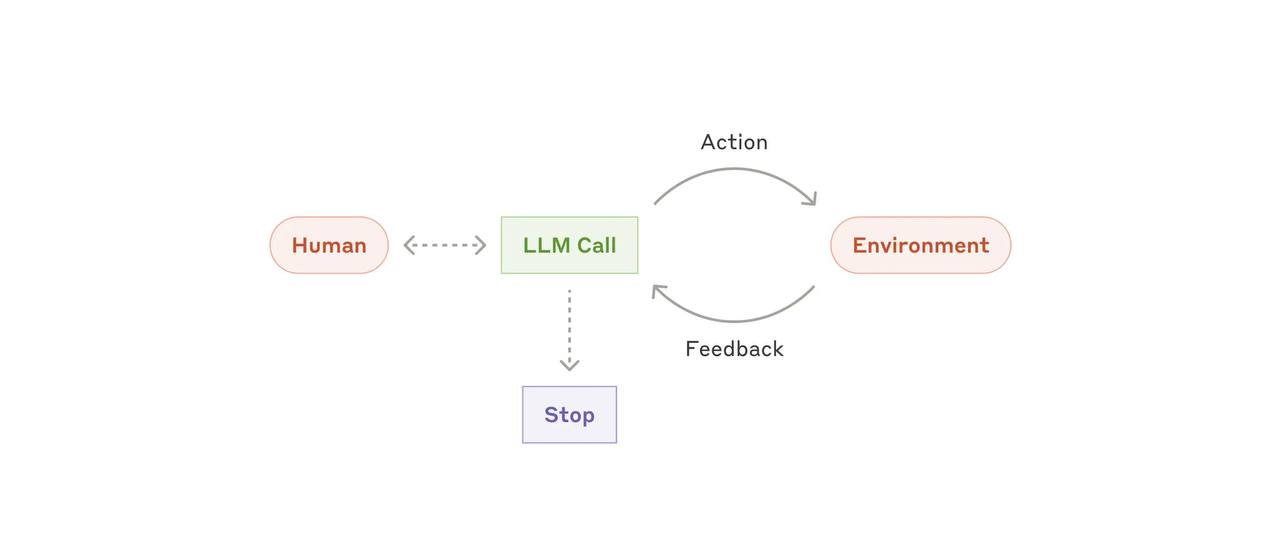
Как создавать LLM-агентов без лишней головной боли (Личный опыт и наблюдения из практики Anthropi...
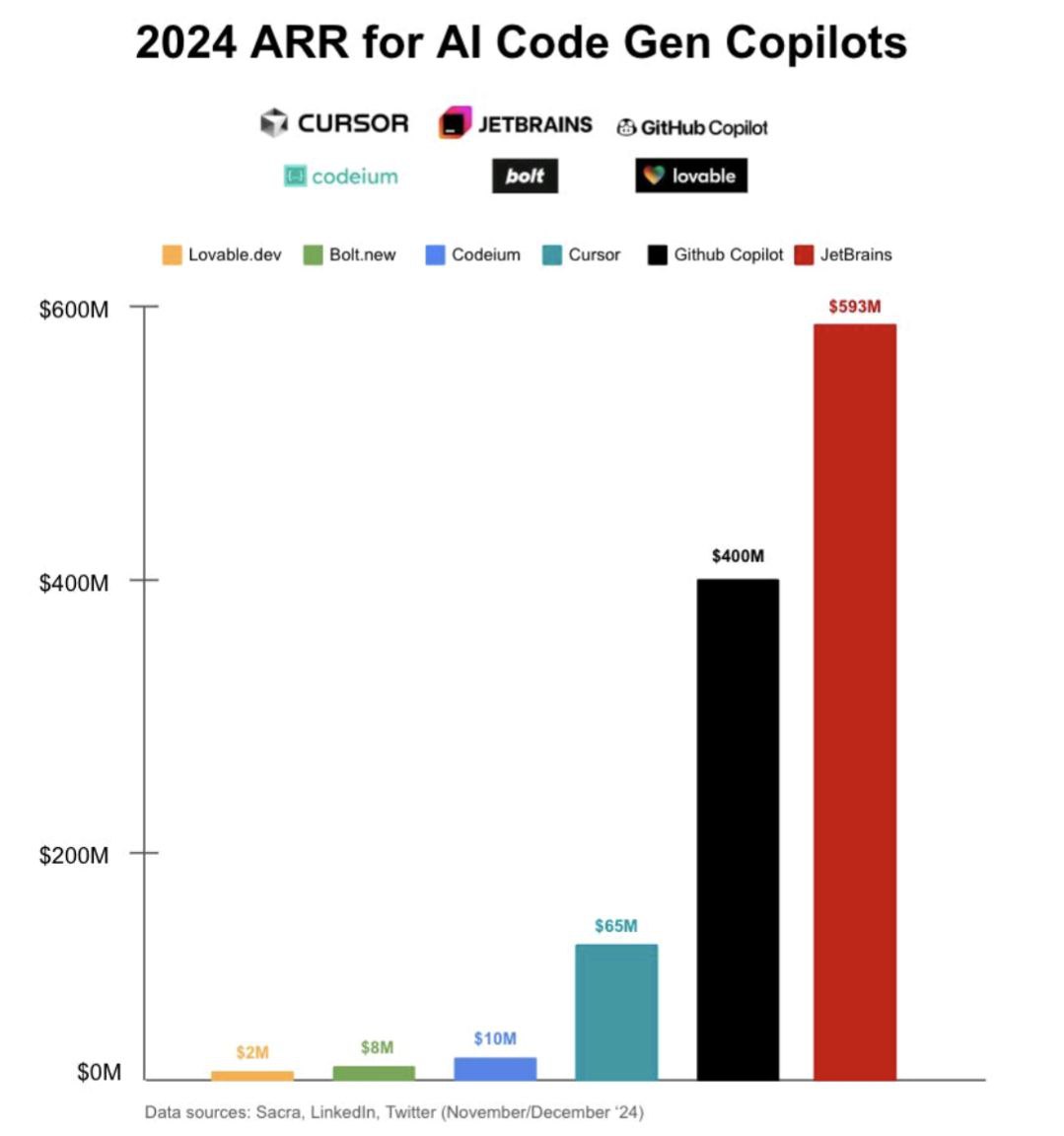
Кто из AI ассистентов для кода заработал больше всех в 2024? Oliver Molander в своем LinkedIn п...