
Ускоряем HNSW: Квантизация для ANN-поиска
Где красивые алгоритмы, там и красивые их ускорения от железа. Квантизация нейросетей — отличный способ уменьшить вес модели, ускорить инференс и жечь меньше электричества без значительных потерь в качестве. Так почему бы не применить этот подход в ANN-поиске?
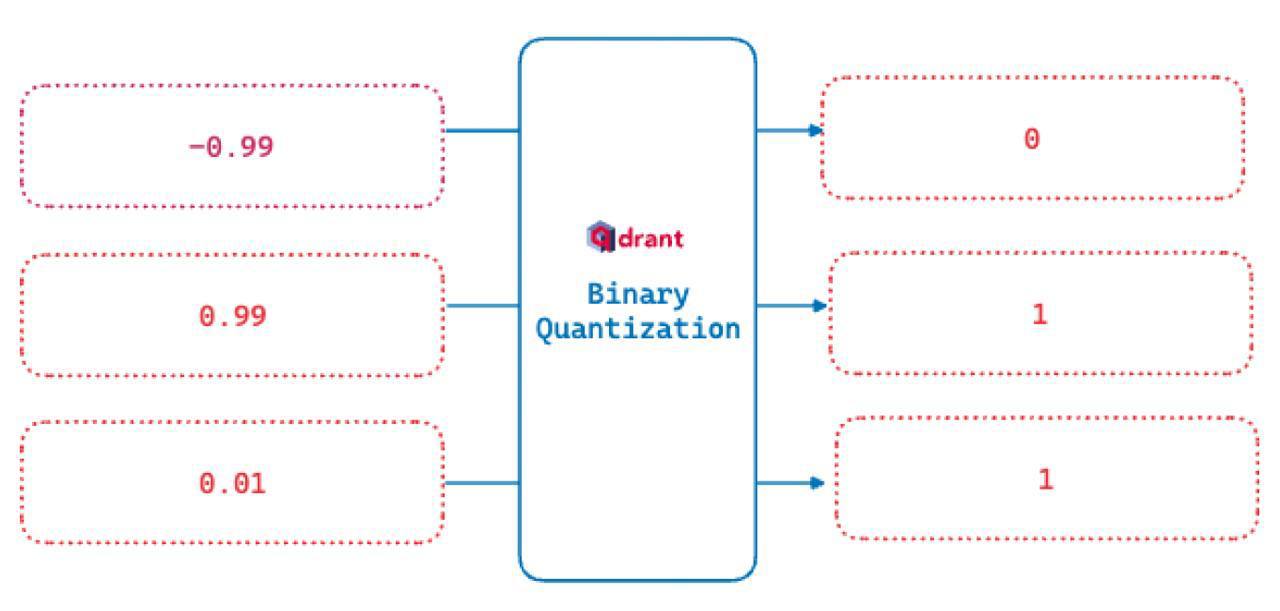
Реализуем это максимально просто и эффективно: заменим все значения больше нуля на единицы, а все, что меньше нуля — на нули. Вот и все, Binary Quantization готова.
Что это дает? Значительное ускорение поиска. Вектор длиной 512 можно упаковать в 64 байта и использовать SIMD-инструкции на CPU. Почему это не сломает поиск? Потому что эмбединги как и сами нейросети содержат множество избыточных параметров, от которых можно избавиться без заметной потери качества. Иногда даже лучше становится!
Оптимальный подход — комбинированный. Сначала строим бинарный индекс, отбираем кандидатов с запасом например в два раза больше чем нам надо объектов, а затем выполняем полноценный поиск (либо в лоб, либо с использованием HNSW). Плюс ко всему, теперь весь бинарный индекс можно хранить в оперативной памяти и загружать полные вектора только по мере необходимости.
Ну все, теперь я вам всю базу рассказал, можно и оригинальный контент следующим постом закинуть.
Где красивые алгоритмы, там и красивые их ускорения от железа. Квантизация нейросетей — отличный способ уменьшить вес модели, ускорить инференс и жечь меньше электричества без значительных потерь в качестве. Так почему бы не применить этот подход в ANN-поиске?
Реализуем это максимально просто и эффективно: заменим все значения больше нуля на единицы, а все, что меньше нуля — на нули. Вот и все, Binary Quantization готова.
Что это дает? Значительное ускорение поиска. Вектор длиной 512 можно упаковать в 64 байта и использовать SIMD-инструкции на CPU. Почему это не сломает поиск? Потому что эмбединги как и сами нейросети содержат множество избыточных параметров, от которых можно избавиться без заметной потери качества. Иногда даже лучше становится!
Оптимальный подход — комбинированный. Сначала строим бинарный индекс, отбираем кандидатов с запасом например в два раза больше чем нам надо объектов, а затем выполняем полноценный поиск (либо в лоб, либо с использованием HNSW). Плюс ко всему, теперь весь бинарный индекс можно хранить в оперативной памяти и загружать полные вектора только по мере необходимости.
Ну все, теперь я вам всю базу рассказал, можно и оригинальный контент следующим постом закинуть.