



LLM под капотом
Канал про разработку продуктов на базе LLM/ChatGPT. Выжимка важных новостей и разборы кейсов. Related channels | Similar channels
12 211
subscribers
Popular in the channel
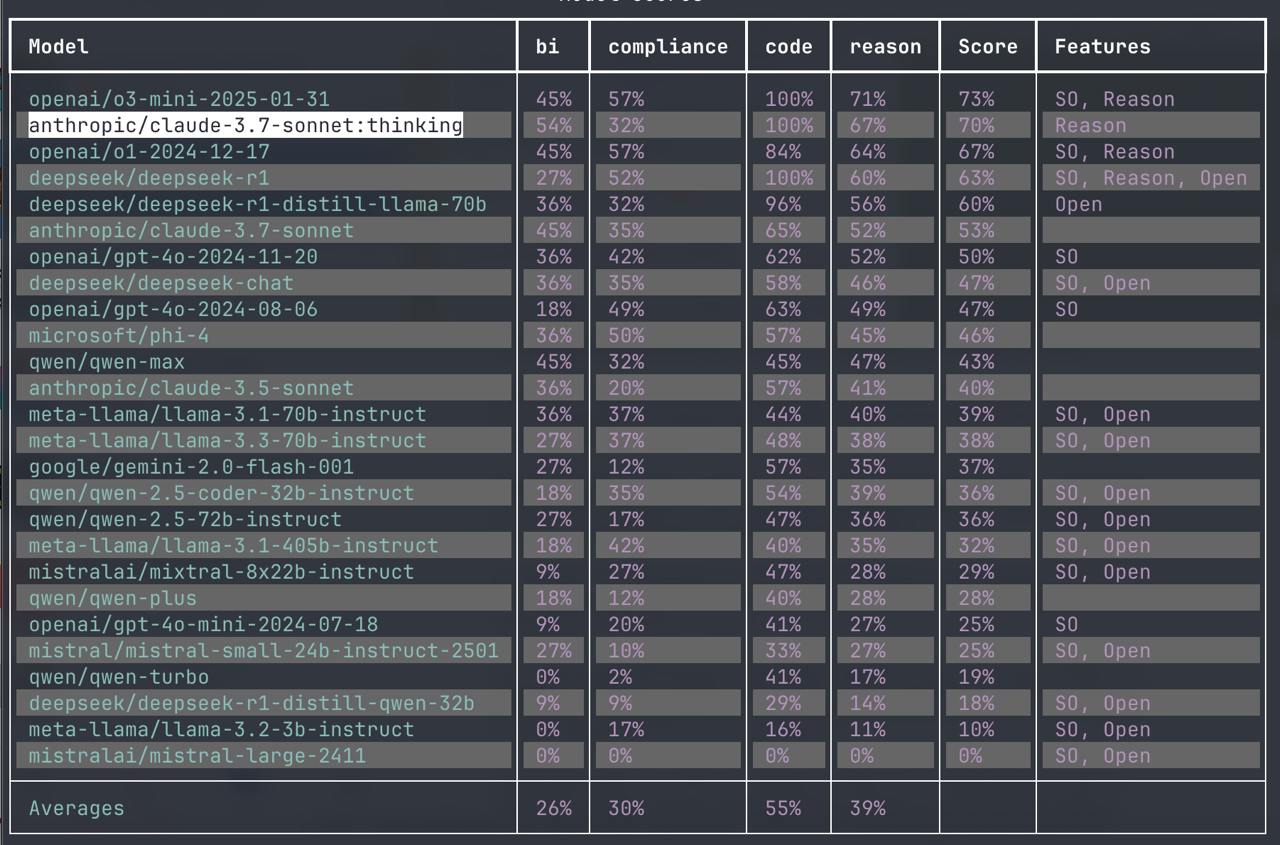
Anthropic Claude 3.7 thinking - второе место! Если вы очень любите Claude, то сделайте себе скри...
Курс “LLM под капотом: выбираем эффективные технические решения для AI-ассистентов” С когортами ...
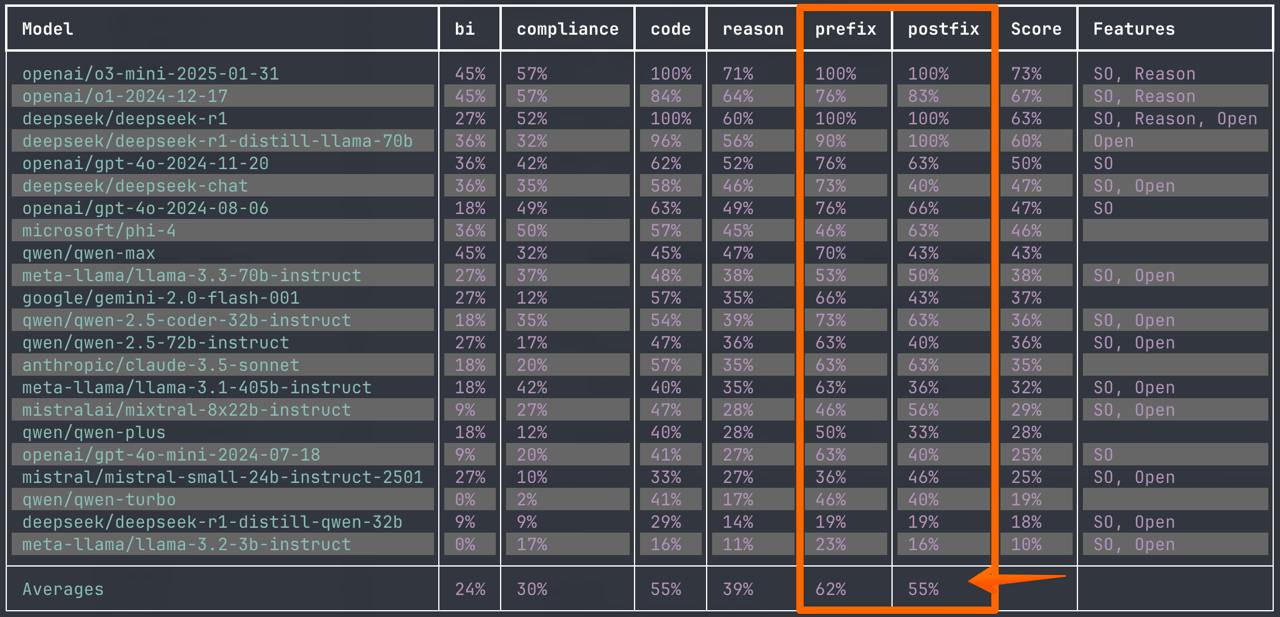
Что лучше - ставить вопрос в промпте до текста или после текста? В прошлом посте про новые бенчм...
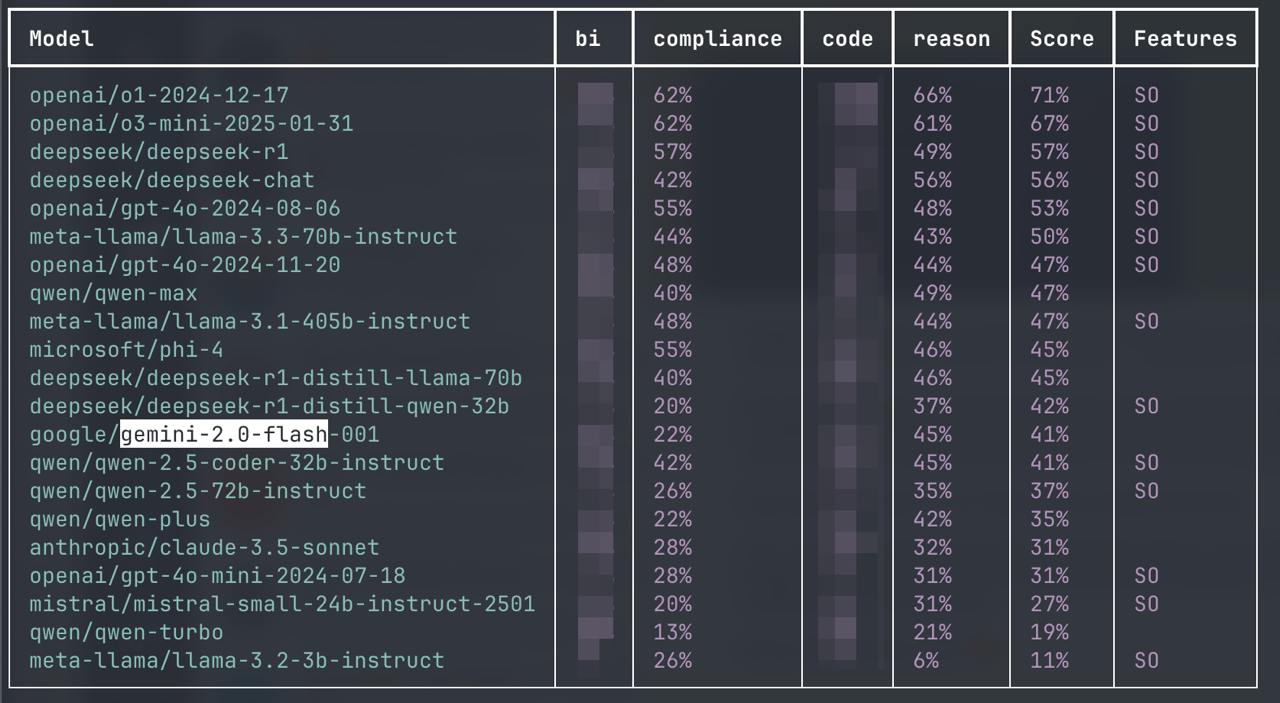
Deepseek V3, Qwen-Max/Plus/Turbo в бенчмарке v2 Продолжаю портировать тесты из AI кейсов во втор...

Как работать с информацией при построении своих RAG систем? Я сейчас собираю материал для дополн...