




AI для Всех
Канал, в котором мы говорим про искусственный интеллект простыми словами
Главный редактор и по рекламе: @crimeacs
Иногда пишут в канал: @GingerSpacetail, @innovationitsme Related channels | Similar channels
14 326
subscribers
Popular in the channel

Калифорнийский Университет запускает AI-систему: что важно знать 🎓 Калифорнийский государственны...
ChatGPT теперь умеет создавать приложения. Как я сделал приложение для изучения языка за пару ми...
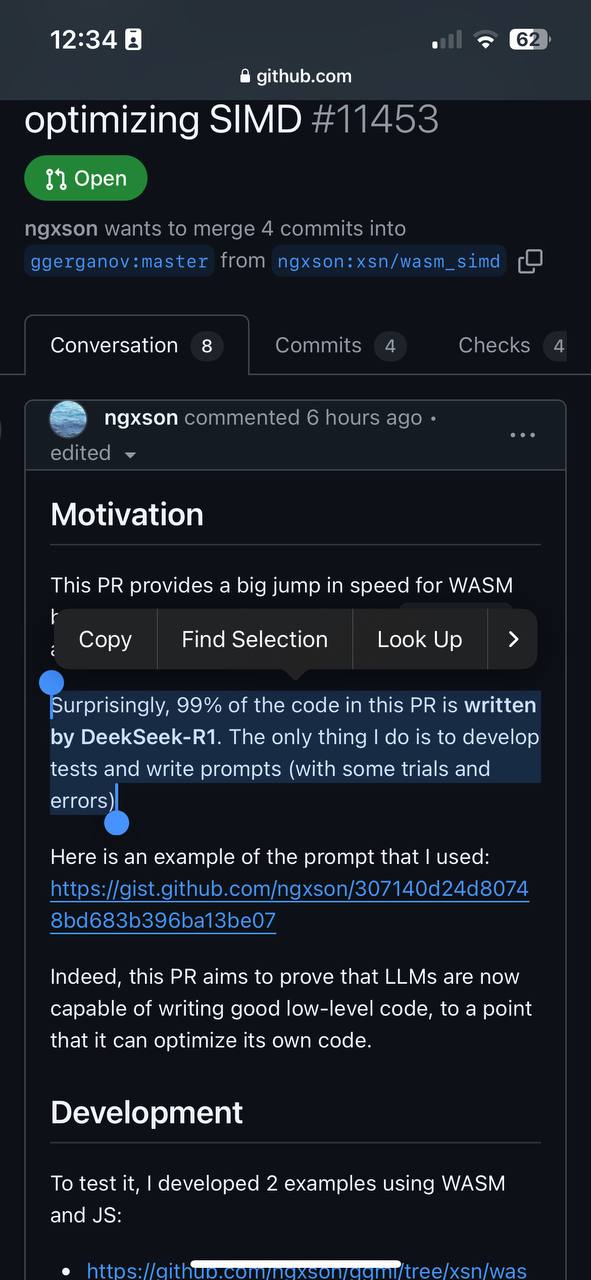
Еще на шаг ближе к сингулярности: ИИ оптимизирует собственный код! 🤖💨 Пока стоки NVIDIA стремите...

🚀 Грандиозный AI-проект Stargate: $500 млрд на будущее искусственного интеллекта Невероятные нов...
ChatGPT Tasks Начал пользоваться Tasks - это новая функция в ChatGPT, которая позволяет создават...