
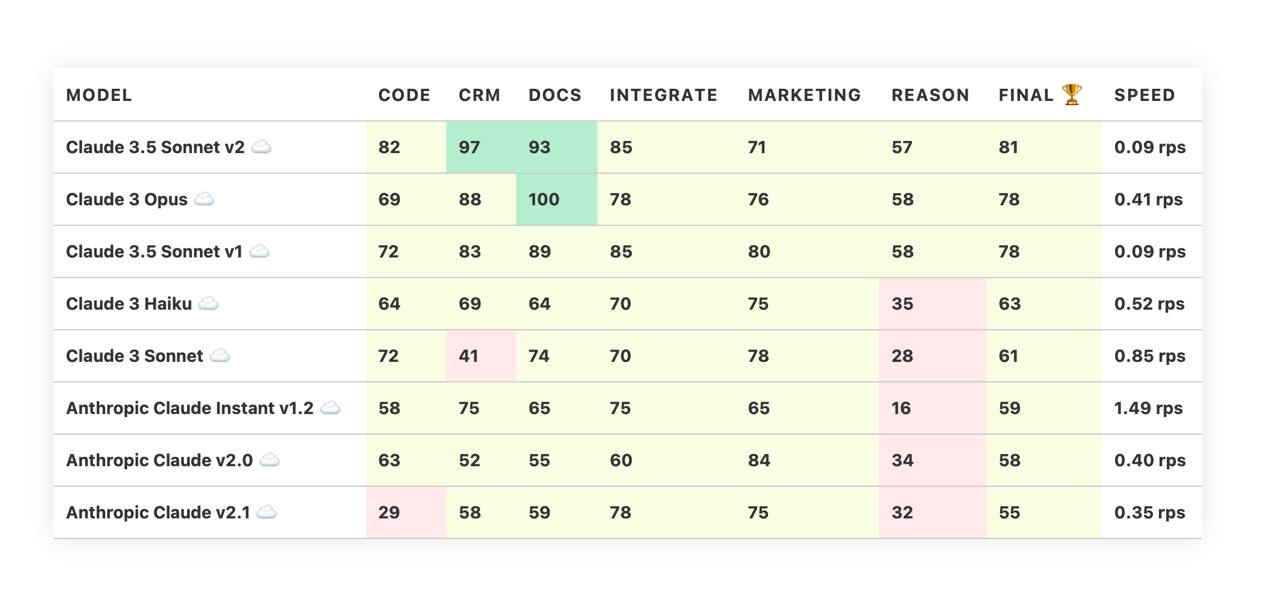
Бенчмарк новой Claude 3.5 Sonnet v2 - лучше прошлой версии, но не TOP 10.
Только что в Anthropic зарелизили Claude 3.5 Sonnet v2. На продуктовом бенчмарке она в TOP 10 не попала, заняв 11ое место в общем зачете.
У новой версии подтянули следование инструкциям и работу с кодом (Code - это не только написание кода, но и анализ, преобразования и рефакторинг).
В целом неплохая модель, но в продуктовых задачах можно получить лучшее качество за меньшие деньги.
Кстати, для тех, кто очень нежно любит качество Claude 3.5 Sonnet в задачах простого написания кода, в комментарии выложу скриншот небольшого бенчмарка для Nodes24 конференции.
Ваш, @llm_under_hood 🤗
PS: Для тех, кто видит эти бенчмарки впервые, напомню - это закрытые продуктовые бенчмарки на основе набора задач из рабочих систем. Мы тестируем не то, как красиво модели болтают, а насколько качественно они выполняют конкретные задачи из продуктов с LLM под капотом. Про структуру и примеры бенчмарков можно прочитать в лабах или на официальном сайте бенчмарков.
Только что в Anthropic зарелизили Claude 3.5 Sonnet v2. На продуктовом бенчмарке она в TOP 10 не попала, заняв 11ое место в общем зачете.
У новой версии подтянули следование инструкциям и работу с кодом (Code - это не только написание кода, но и анализ, преобразования и рефакторинг).
В целом неплохая модель, но в продуктовых задачах можно получить лучшее качество за меньшие деньги.
Кстати, для тех, кто очень нежно любит качество Claude 3.5 Sonnet в задачах простого написания кода, в комментарии выложу скриншот небольшого бенчмарка для Nodes24 конференции.
Ваш, @llm_under_hood 🤗
PS: Для тех, кто видит эти бенчмарки впервые, напомню - это закрытые продуктовые бенчмарки на основе набора задач из рабочих систем. Мы тестируем не то, как красиво модели болтают, а насколько качественно они выполняют конкретные задачи из продуктов с LLM под капотом. Про структуру и примеры бенчмарков можно прочитать в лабах или на официальном сайте бенчмарков.