
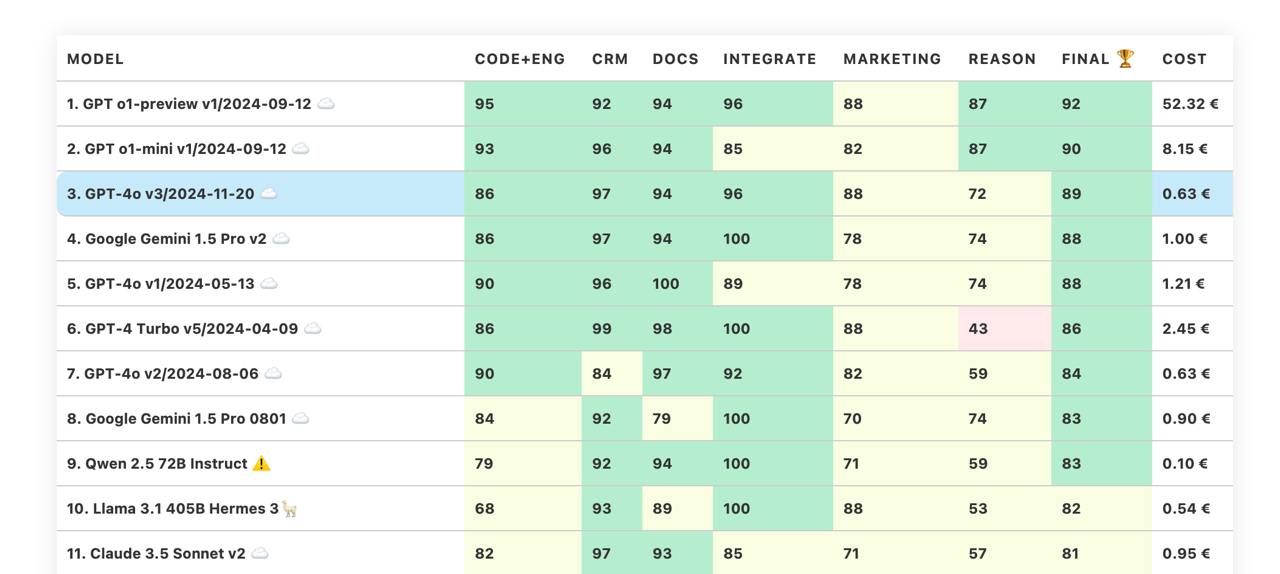
Новая GPT-4o - третье место в бенчмарке 🎉
Новая версия GPT-4o от OpenAI выглядит очень хорошо и недорого (`gpt-4o-2024-11-20` в API). OpenAI даже не особо писали про эту модель - просто опубликовали пост в X:
Хотя, по-моему, отдельного поста эта модель заслуживает. По сравнению с прошлой GPT-4o v2/2024-08-06 - это значительный скачок по множеству параметров, включая Reason (59 - 72). А если учесть и цену, то это новый претендент на использование модели в новых проектах по дефолту.
Приятно видеть, что в этой ценовой категории прогресс пока не остановился. Возможно, использование o1 для генерации синтетики для обучения, позволит сохранить динамику на месяцы вперед.
Кстати, толкотня на вершине бенчмарка (score saturation) меня достаточно раздражает, поэтому следующий свободный R&D блок в TimeToAct я выделю на разработку второй версии бенчмарка. Благо кейсов набралось более, чем достаточно.
Ваш, @llm_under_hood 🤗
PS: Для тех, кто видит эти бенчмарки впервые, напомню - это закрытые продуктовые бенчмарки на основе набора задач из рабочих систем. Мы тестируем не то, как красиво модели болтают, а насколько качественно они выполняют конкретные задачи из продуктов с LLM под капотом. Про структуру и примеры бенчмарков можно прочитать в лабах или на официальном сайте бенчмарков.
Новая версия GPT-4o от OpenAI выглядит очень хорошо и недорого (`gpt-4o-2024-11-20` в API). OpenAI даже не особо писали про эту модель - просто опубликовали пост в X:
GPT-4o got an update 🎉
The model’s creative writing ability has leveled up–more natural, engaging, and tailored writing to improve relevance & readability.
It’s also better at working with uploaded files, providing deeper insights & more thorough responses.
Хотя, по-моему, отдельного поста эта модель заслуживает. По сравнению с прошлой GPT-4o v2/2024-08-06 - это значительный скачок по множеству параметров, включая Reason (59 - 72). А если учесть и цену, то это новый претендент на использование модели в новых проектах по дефолту.
Приятно видеть, что в этой ценовой категории прогресс пока не остановился. Возможно, использование o1 для генерации синтетики для обучения, позволит сохранить динамику на месяцы вперед.
Кстати, толкотня на вершине бенчмарка (score saturation) меня достаточно раздражает, поэтому следующий свободный R&D блок в TimeToAct я выделю на разработку второй версии бенчмарка. Благо кейсов набралось более, чем достаточно.
Ваш, @llm_under_hood 🤗
PS: Для тех, кто видит эти бенчмарки впервые, напомню - это закрытые продуктовые бенчмарки на основе набора задач из рабочих систем. Мы тестируем не то, как красиво модели болтают, а насколько качественно они выполняют конкретные задачи из продуктов с LLM под капотом. Про структуру и примеры бенчмарков можно прочитать в лабах или на официальном сайте бенчмарков.