
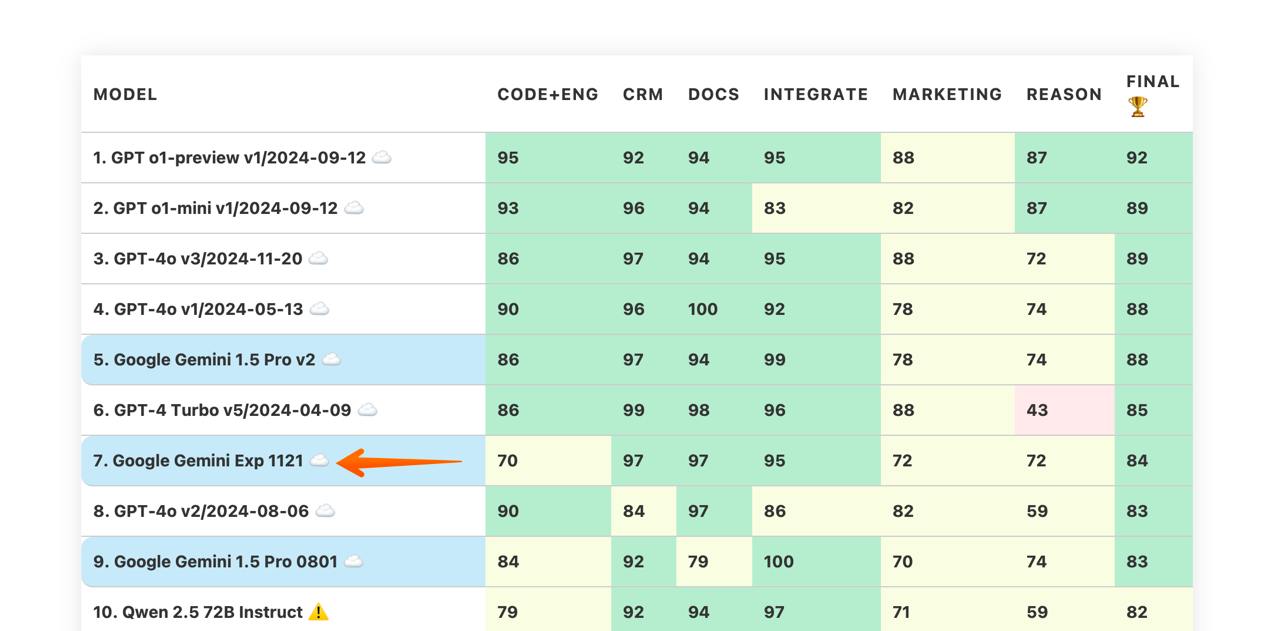
Бенчмарк Gemini Experimental 1121 - седьмое место, unobtanium
Google освоились с LLM, они продолжают выпускать модели, которые кучно попадают в TOP 10. Новая экспериментальная версия повторяет этот тренд. Она немного хуже топовой Gemini 1.5 Pro, особенно в автоматизации задач из Code+Eng. Но хороший reason дает основание ожидать, что модель только станет лучше.
Почему модель - unobtanium? Да потому, что ее пока нигде не достать. Она доступна либо на OpenRouter либо на Google AI Studio с такими дикими rate limits, что на бенчмарк ушло несколько дней и API ключей.
Ваш, @llm_under_hood 🤗
PS: Для тех, кто видит бенчмарки впервые, подробнее про них написано тут.
Google освоились с LLM, они продолжают выпускать модели, которые кучно попадают в TOP 10. Новая экспериментальная версия повторяет этот тренд. Она немного хуже топовой Gemini 1.5 Pro, особенно в автоматизации задач из Code+Eng. Но хороший reason дает основание ожидать, что модель только станет лучше.
Почему модель - unobtanium? Да потому, что ее пока нигде не достать. Она доступна либо на OpenRouter либо на Google AI Studio с такими дикими rate limits, что на бенчмарк ушло несколько дней и API ключей.
Ваш, @llm_under_hood 🤗
PS: Для тех, кто видит бенчмарки впервые, подробнее про них написано тут.