
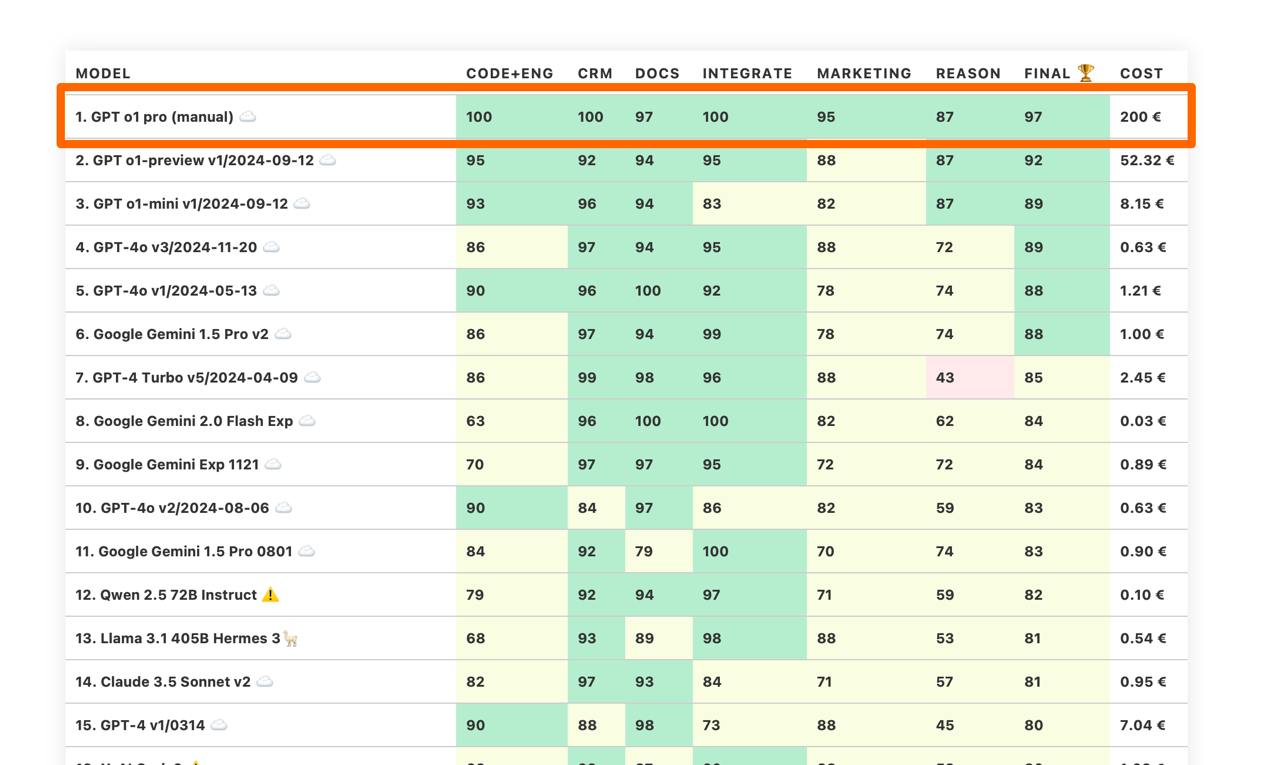
Бенчмарк o1 pro - золотой стандарт
Итак, настало время протестировать o1 pro.
Но сначала disclaimer. Есть 4 разные версии o1. Не путайте их!
- o1-mini - самая маленькая и недорогая из Reasoning моделей. Она есть в ChatGPT и по API
- o1-preview - мощная версия, которая раньше была доступна в ChatGPT интерфейсе. Теперь ее оттуда убрали и заменили на pro. По API она еще доступна
- o1 - это то, что теперь заменяет o1-preview в чат интерфейсе. У этой модели ограничено время на размышления, так что субъективно она заметно глупее preview. По API эта модель не доступна.
- o1 pro - самая мощная модель, которой разрешили думать много и долго. Она есть в чат интерфейсе по Pro подписке за $200. По API ее пока нет.
Этот пост - исключительно про o1 pro. Модель я в порядке исключения тестировал вручную.
Я взял результаты бенчмарка o1-mini, и выбрал те задачи, в которых она ошибалась. o1 pro на голову выше mini, поэтому я допустил, что если mini не ошиблась, то и pro не ошибется. Таким образом мне нужно было прогнать не пару сотен задач, а в десять раз меньше.
Еще я отключил custom instructions по своевременному совету Игоря. Память у меня и так была отключена. Сконвертировал запросы к API в текстовый запрос и запустил вречную.
Тут я столкнулся с двумя граблями.
Во-первых, o1 pro сейчас встроена в Chat. Поэтому задачки, которые по API возвращали нормальный plain-text YAML, теперь стали возвращать красиво отформатированный markdown. Тут я исправлял формат вручную.
Во-вторых, я при задачах в API я few-shots всегда форматировал так:
System: Task explanation
User: sample request 1
Assistant: sample response 1
User: sample request 2
Assistant: sample response 2
User: real request
Но с чатом такое не прокатит, нужно формировать все в один текст. Более того, системный промпт нам не доступен в o1 моделях в принципе, чтобы случайно не утекло содержимое reasoning (ибо оно генерируется моделями без alignment). И вообще модель накручена защищать системный промпт и работать с пользователем в диалоге.
В итоге, o1 pro понижала приоритет инструкций, которые были помечены как System и начинала искать паттерны в запросах пользователя. Она их находила и приходила к неверным выводам, спотыкаясь на integrate. Поэтому задачу в текстовый UI я стал форматировать так:
# Task
Task explanation
## Example
User:
Assistant:
## Example
User:
Assistant:
# Request
Ну а что в итоге?
o1 pro подобралась вплотную к потолку моего продуктового бенчмарка, набрав 97. Причем нехватающие 3 балла можно даже было бы оспорить. В рамках бенчмарка она как золотой стандарт - дорога и идеальна.
Это очень хорошо. В разработке второй версии бенчмарка я смогу отталкиваться от этого потолка и формулировать задачи так, чтобы на самых сложных засыпалась даже o1 pro. Это позволит выстроить более плавную кривую оценок и сделать бенчмарк более репрезентативным для сложных кейсов LLM в бизнесе и продуктах.
Ваш, @llm_under_hood 🤗
PS: Для тех, кто видит бенчмарки впервые, подробнее про них написано тут.
Итак, настало время протестировать o1 pro.
Но сначала disclaimer. Есть 4 разные версии o1. Не путайте их!
- o1-mini - самая маленькая и недорогая из Reasoning моделей. Она есть в ChatGPT и по API
- o1-preview - мощная версия, которая раньше была доступна в ChatGPT интерфейсе. Теперь ее оттуда убрали и заменили на pro. По API она еще доступна
- o1 - это то, что теперь заменяет o1-preview в чат интерфейсе. У этой модели ограничено время на размышления, так что субъективно она заметно глупее preview. По API эта модель не доступна.
- o1 pro - самая мощная модель, которой разрешили думать много и долго. Она есть в чат интерфейсе по Pro подписке за $200. По API ее пока нет.
Этот пост - исключительно про o1 pro. Модель я в порядке исключения тестировал вручную.
Я взял результаты бенчмарка o1-mini, и выбрал те задачи, в которых она ошибалась. o1 pro на голову выше mini, поэтому я допустил, что если mini не ошиблась, то и pro не ошибется. Таким образом мне нужно было прогнать не пару сотен задач, а в десять раз меньше.
Еще я отключил custom instructions по своевременному совету Игоря. Память у меня и так была отключена. Сконвертировал запросы к API в текстовый запрос и запустил вречную.
Тут я столкнулся с двумя граблями.
Во-первых, o1 pro сейчас встроена в Chat. Поэтому задачки, которые по API возвращали нормальный plain-text YAML, теперь стали возвращать красиво отформатированный markdown. Тут я исправлял формат вручную.
Во-вторых, я при задачах в API я few-shots всегда форматировал так:
System: Task explanation
User: sample request 1
Assistant: sample response 1
User: sample request 2
Assistant: sample response 2
User: real request
Но с чатом такое не прокатит, нужно формировать все в один текст. Более того, системный промпт нам не доступен в o1 моделях в принципе, чтобы случайно не утекло содержимое reasoning (ибо оно генерируется моделями без alignment). И вообще модель накручена защищать системный промпт и работать с пользователем в диалоге.
В итоге, o1 pro понижала приоритет инструкций, которые были помечены как System и начинала искать паттерны в запросах пользователя. Она их находила и приходила к неверным выводам, спотыкаясь на integrate. Поэтому задачу в текстовый UI я стал форматировать так:
# Task
Task explanation
## Example
User:
Assistant:
## Example
User:
Assistant:
# Request
Ну а что в итоге?
o1 pro подобралась вплотную к потолку моего продуктового бенчмарка, набрав 97. Причем нехватающие 3 балла можно даже было бы оспорить. В рамках бенчмарка она как золотой стандарт - дорога и идеальна.
Это очень хорошо. В разработке второй версии бенчмарка я смогу отталкиваться от этого потолка и формулировать задачи так, чтобы на самых сложных засыпалась даже o1 pro. Это позволит выстроить более плавную кривую оценок и сделать бенчмарк более репрезентативным для сложных кейсов LLM в бизнесе и продуктах.
Ваш, @llm_under_hood 🤗
PS: Для тех, кто видит бенчмарки впервые, подробнее про них написано тут.